Dailyge Infra 저장소 입니다.
서비스 소개는 해당 링크를 참조해주세요. 😃



- Skills
- CI/CD
- Architecture
- Contents
- Modules
서비스 구축을 위해 AWS를 활용했으며, Terraform을 사용해 자원을 프로비저닝 했습니다. Terraform으로 관리되는 자원은 Route53, CloudFront, S3, ALB, ECS, EC2(Application), RD 이며, 일부 자원들은 설치형으로 사용하고 있습니다. 모니터링은 Prometheus와 Grafana를 사용하고 있으며, 운영 및 시스템 로그는 모두 AWS CloudWatch로 관리하고 있습니다.

운영 과정에서 발생하는 이슈는 Grafana Alert 또는 AWS Lambda를 통해 슬랙으로 보고받고 있으며, Lambda와 같은 일부 서비스는 Python을 사용 중입니다.
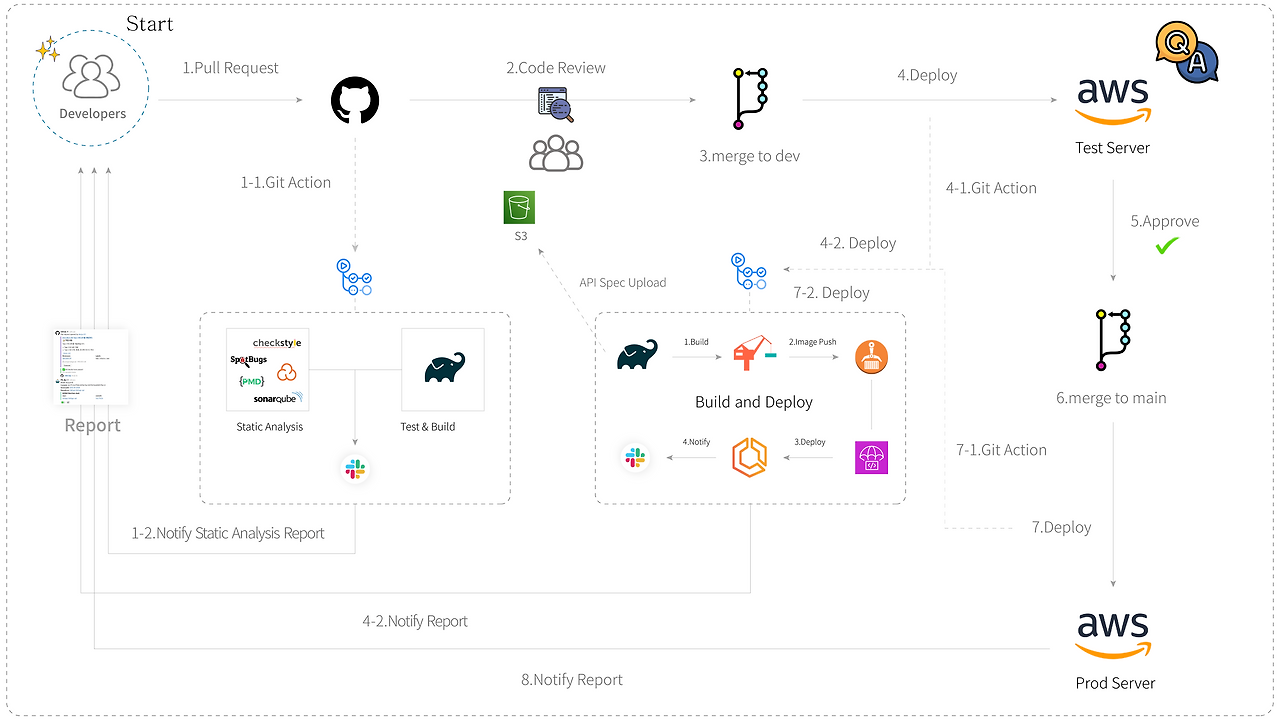
PR이 생성되면 자동으로 정적 분석을 시작하며, Slack으로 결과를 보고받습니다. 팀원 간 코드 리뷰를 거친 후, dev 브랜치로 병합이 되면 개발 서버로 배포가 되며, 인수 테스트가 시작됩니다. 자동 인수 테스트 외에도 QA를 진행하며 기능의 동작 유무, 버그 리포팅을 합니다. main 브랜치로 병합이 되면 상용 서버로 배포가 되며, 최종 결과를 보고받습니다.
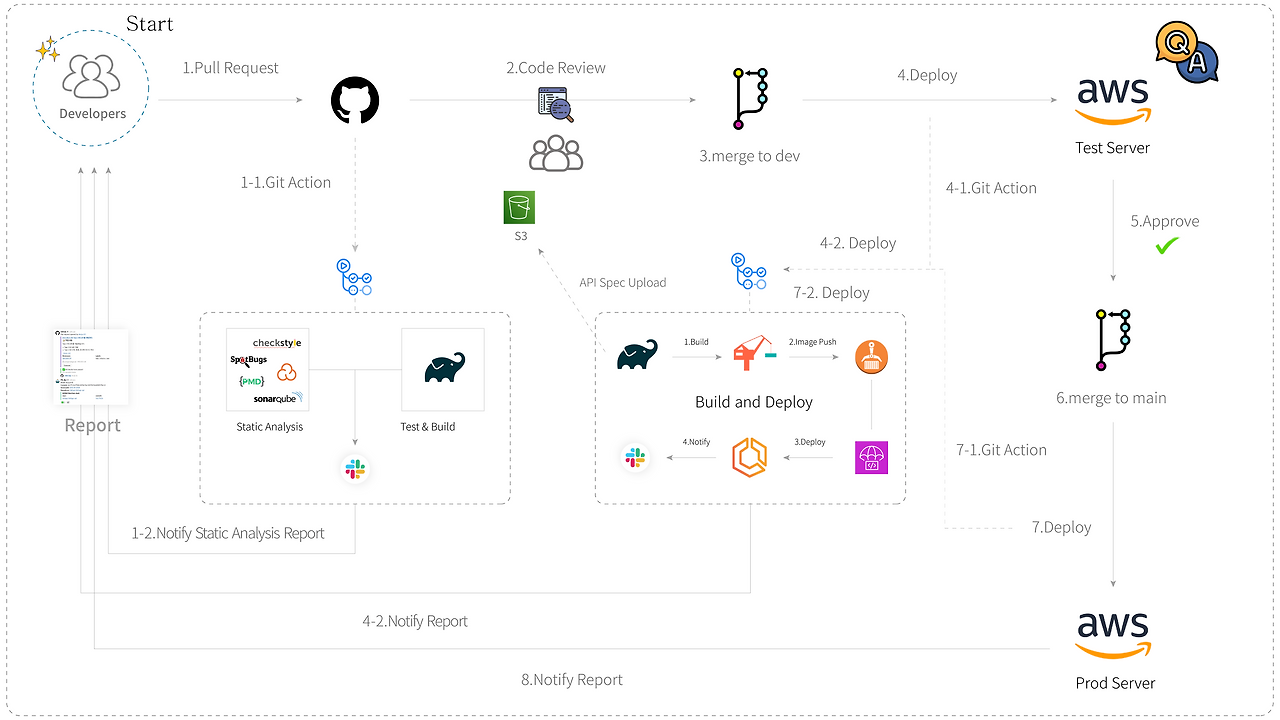
테스트, 배포 결과 및 비용은 슬랙을 통해 확인하고 있습니다.

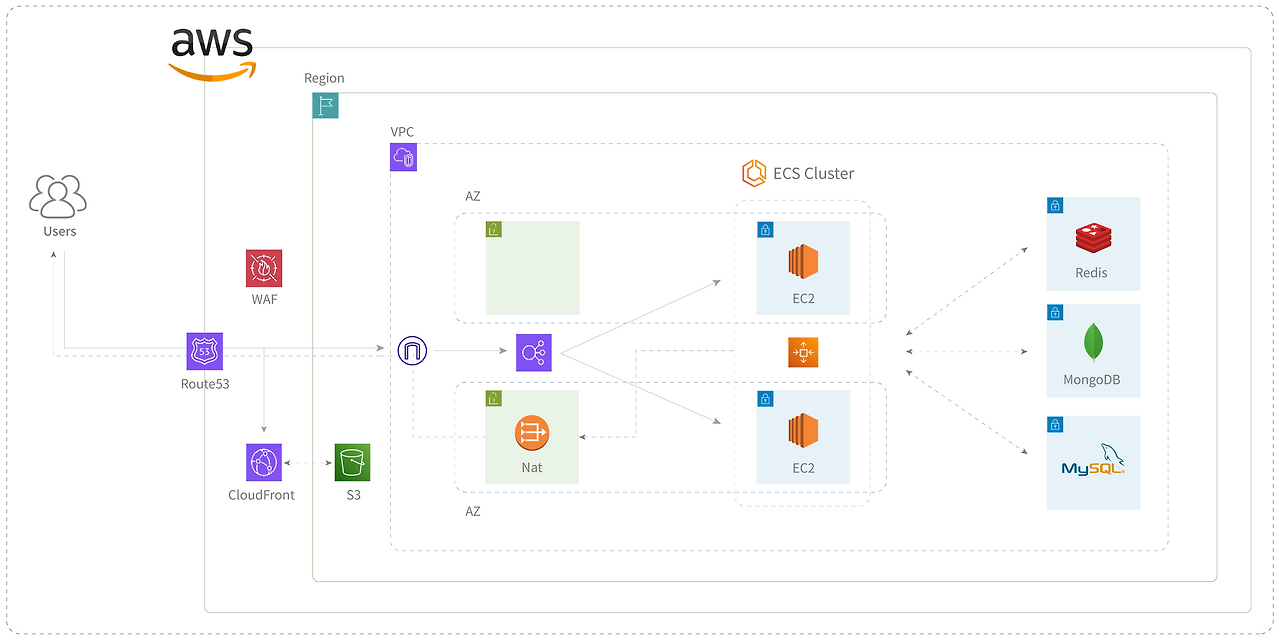
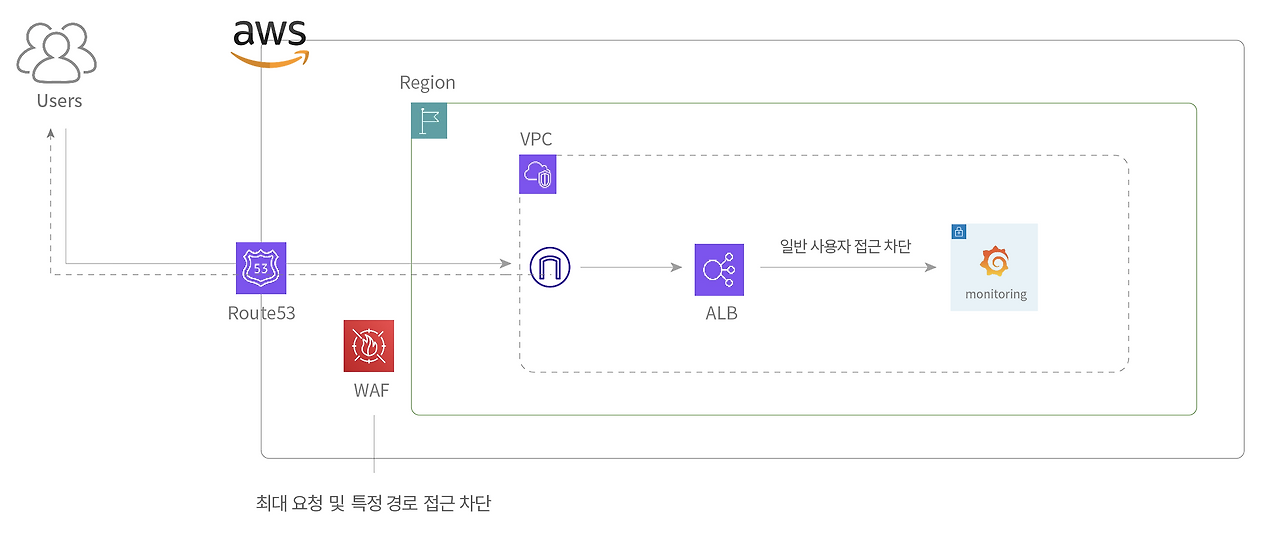
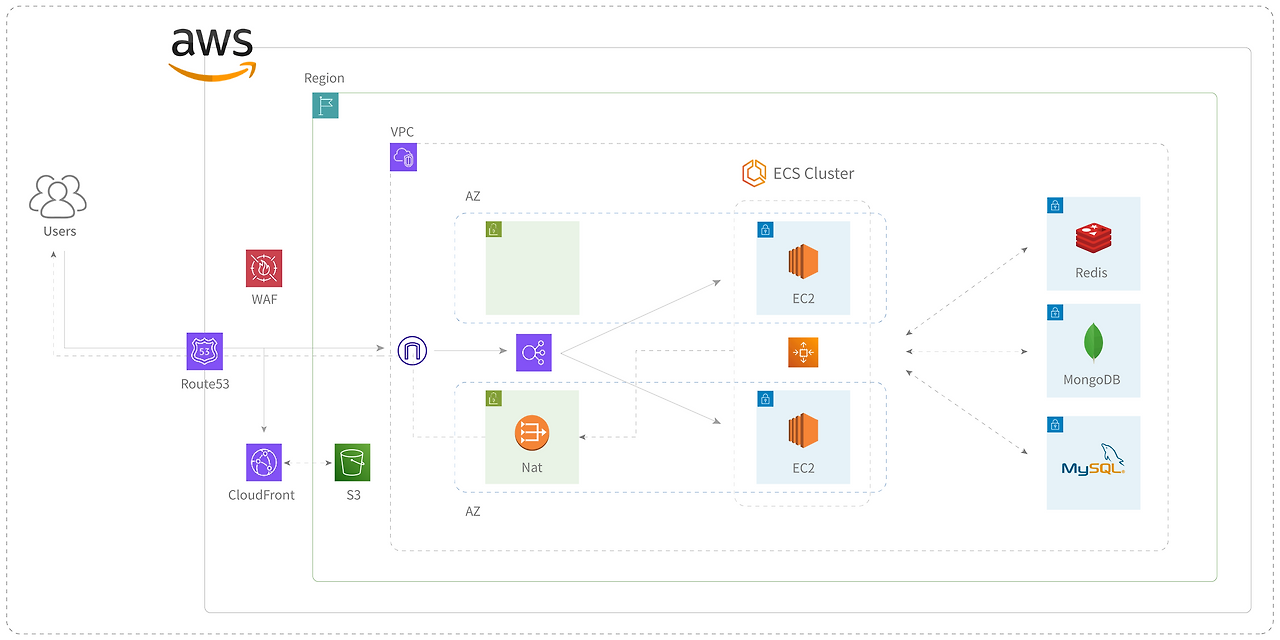
정적 자원은 S3와 CloudFront를, 서버 오케스트레이션은 AWS ECS를 사용했습니다. 각 리소스는 VPC 내부 별도의 서브넷(Public/Private)에 존재하며, ALB와 NAT를 통해 외부와 통신합니다. 부하 테스트를 할 때는 terraform을 통해 서버를 동적으로 확장하고 있으며, 평상시에는 최소 인스턴스만 사용하고 있습니다.
서브 도메인을 적극 활용하고 있으며, 서브 도메인 간 쿠키를 공유해 사용하고 있습니다. 개발 서버, 모니터링 서버와 같은 서브 도메인에 대한 접근은 WAF 및 Security Group으로 관리하고 있습니다.
- Resource 관리
- Config 관리
- Server
- RateLimiter
- Monitoring
- Log
- DB 백업
프로비저닝을 후, 변경될 일이 적은 자원 들, 데이터베이스같이 변경되어선 안 되는 자원 들은 ignore_changes를 통해 테라폼 라이프사이클에서 제외한 후, 관리하고 있습니다.
resource "aws_cloudfront_distribution" "s3_distribution_tasks_dev" {
......
lifecycle {
ignore_changes = all
}
}
Git Submodule과 AWS Secret Manager를 사용해 환경 변수를 관리하고 있습니다.
외부에 노출되는 값들은 암호화된 상태로 노출됩니다.
env:
dev
profile:
email: ENC(EoatZjyTeks503/9neDp3JfrFlhWwAiRvlYd77599hM=)
nickname: ENC(VA1R4pL0mo0xHTfV68j+3xQrJbffCBTb)
spring:
cloud:
aws:
region:
static: ap-northeast-2
credentials:
access-key: ENC(5vaRGdYWZUJsFEFF5P8A06TkwwNl5eapE)
secret-key: ENC(JdK2itnFEFDKOdRu7A7zcXmLpOZwbSEWRUwq)
liquibase:
enabled: true
change-log: db/rdb/changelog/changelog-master.yaml
datasource:
url: ENC(qmiZS71LFX29baI8nNpBKhLlLmsJop5vaRGdYWZUJsFEFF5P8A06TkwwNl5eapyY6/vlVdD6zCLkE8qlJdK2itnMByBKOdRu7A7zcXmLpOZwbSEWRUwqGbRvspsUPEFO/sS0PAqBF25vddL6GJ11onkUFqJZ0hPJt3Qr6toHqXcTH7yZNHlrTMLb2xrPlWU)
username: ENC(KHdUpehLSIMFEEyDjj8P/+w==)
password: ENC(/KquPoFfhpYAFEFSsumXHPpsdkquc4M)
driver-class-name: com.mysql.cj.jdbc.Driver
......
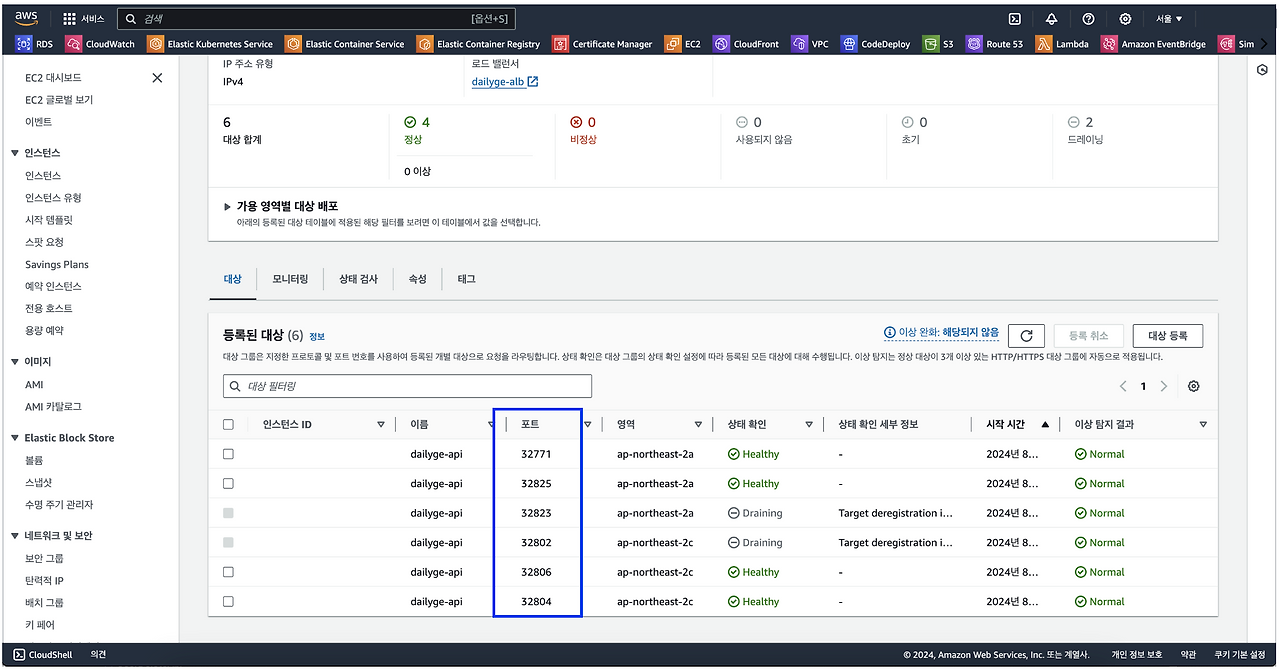
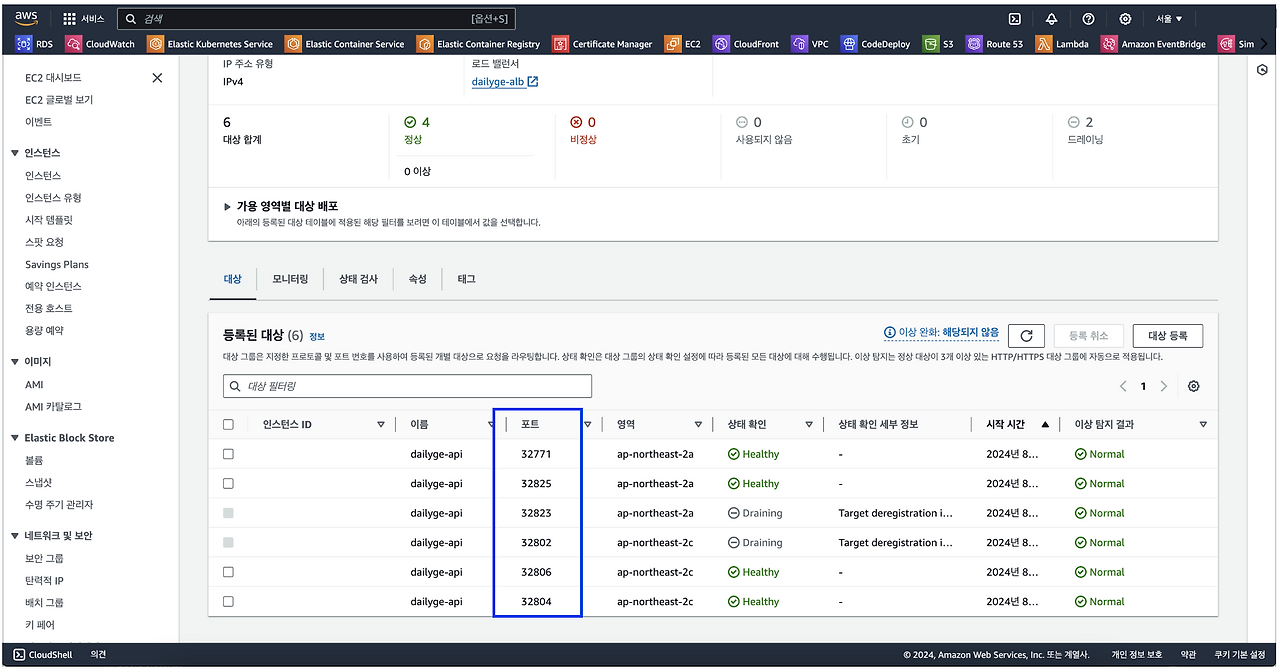
리소스 및 오토 스케일링을 조금 더 세밀하게 제어하기 위해 Fargate 대신 EC2를 사용하고 있으며, 배포 및 포트 충돌 방지를 위해 ECS 동적 포트를 사용하고 있습니다.
Route53에서 WAF로 일정 시간 동안 최대 사용자 요청을 제한하고 있으며, 모니터링 서버, 관리자 API 등 특정 리소스에 대한 접근은 ALB와 WAF, Security Group으로 제한하고 있습니다.
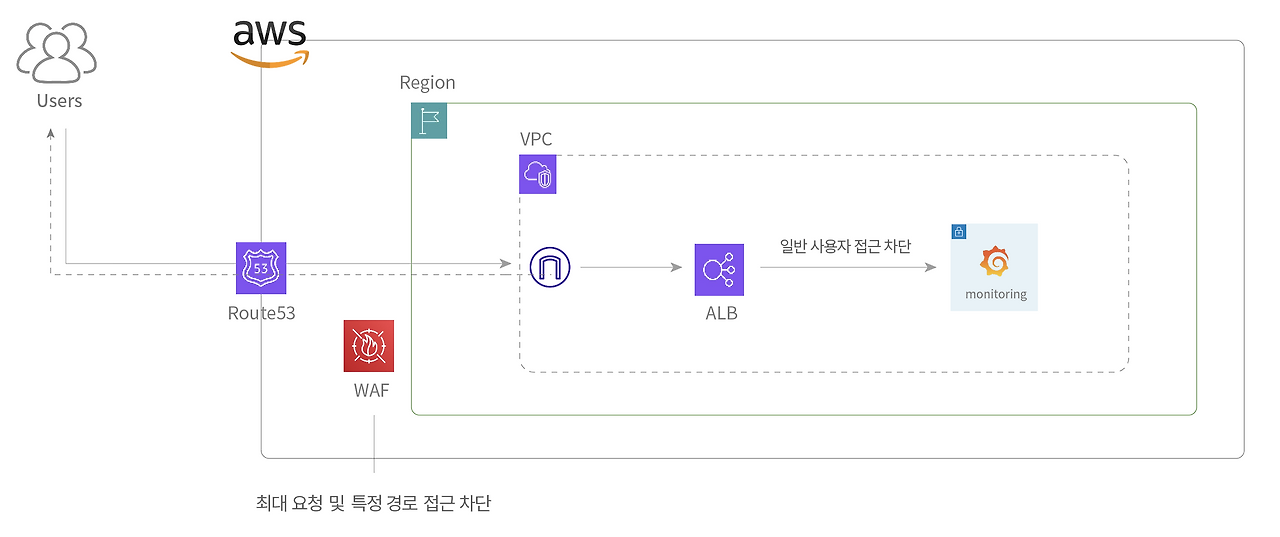
평소에는 분당 1,000회 이상일 때, IP 기반으로 API 요청 제한을 걸고 있으며, 부하 테스트를 할 때, 이를 해제합니다.
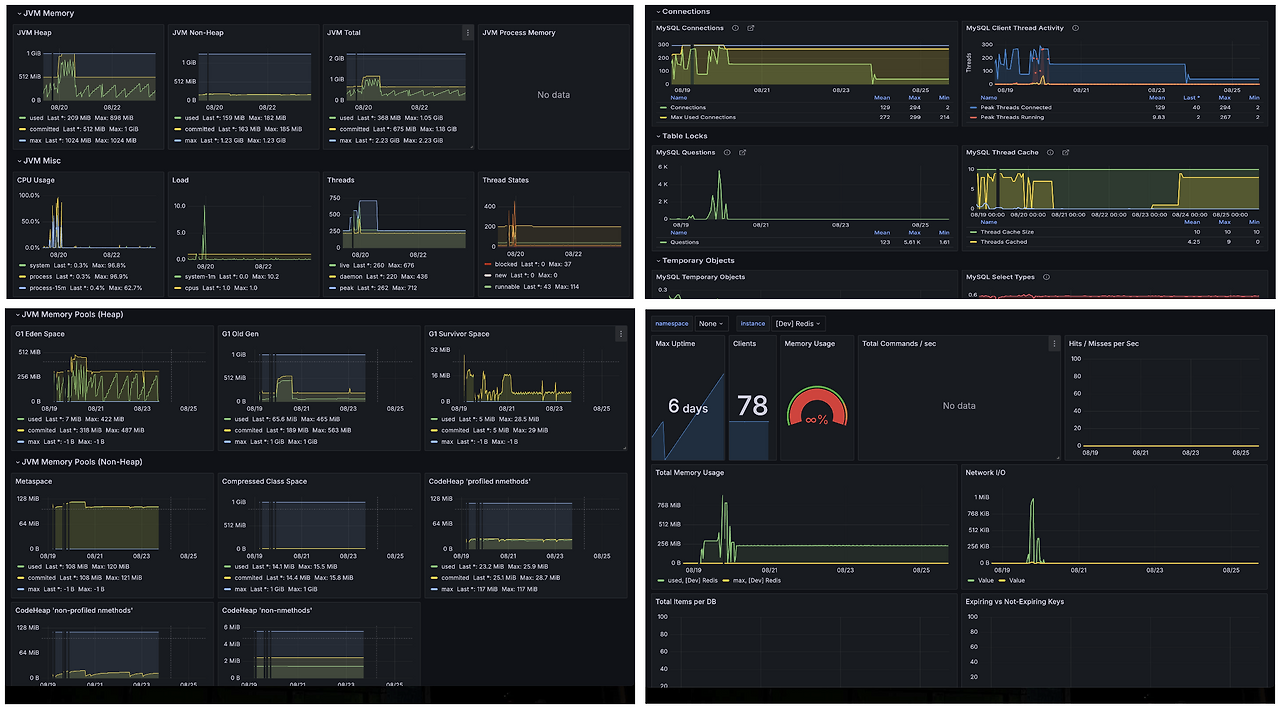
모니터링은 Prometheus와 Grafana를 CloudWatch와 연동해 사용하고 있으며, 이를 통해 알림을 받고 있습니다. 모니터링 중인 리소스는 EC2 서버, 애플리케이션 지표, RDS, Redis, MongoDB이며, CPU/메모리 사용률, Slow Query 등을 체크하고 있습니다.
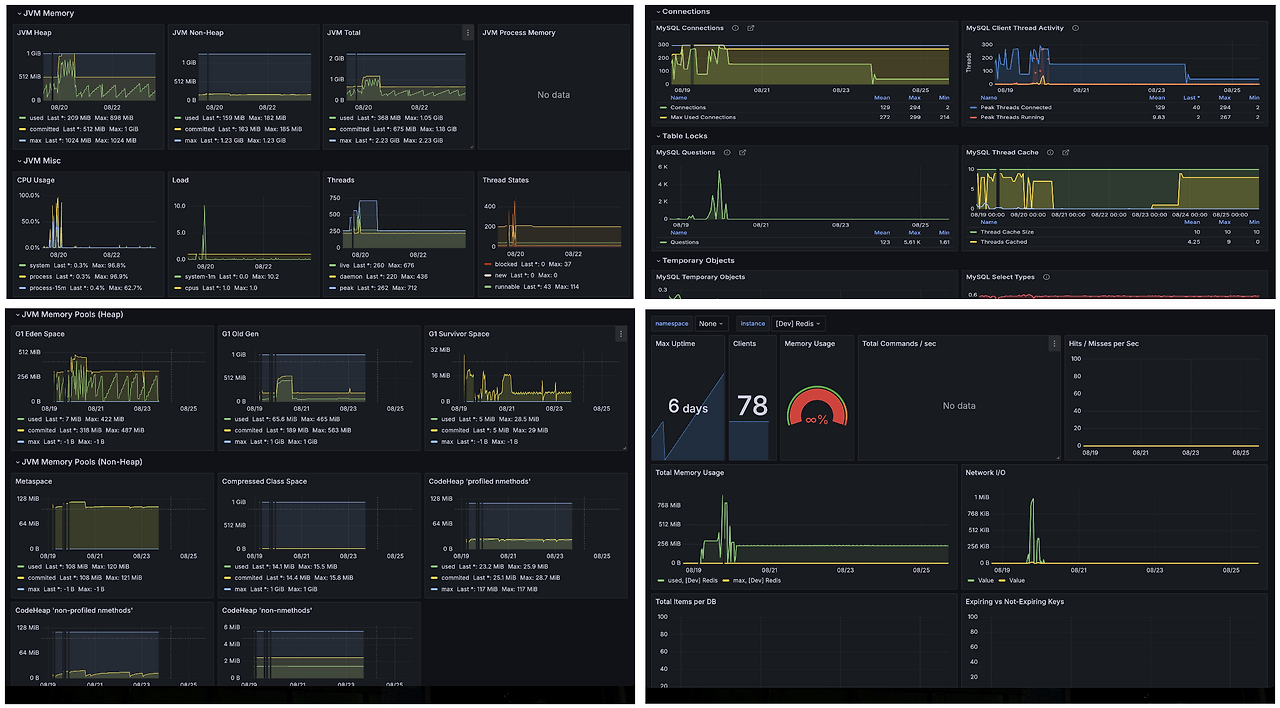
애플리케이션이 다운될 경우, 자동으로 힙 덤프를 생성한 후, 이를 정적 저장소로 업로드하고 알림을 보내고 있습니다.
오토 스케일링은 CPU 사용률이 75% 이상일 때, 1분 이상 지속되면 동작합니다. 이는 CloudWatch와 연동하고 있으며, 이 부분은 테라폼이 아닌 설치형으로 관리하고 있습니다.
resource "aws_appautoscaling_policy" "dailyge_api_scale_out_policy" {
name = "dailyge-api-scale-out-policy"
policy_type = "TargetTrackingScaling"
resource_id = aws_appautoscaling_target.dailyge_api_ecs_scaling_target.resource_id
scalable_dimension = aws_appautoscaling_target.dailyge_api_ecs_scaling_target.scalable_dimension
service_namespace = aws_appautoscaling_target.dailyge_api_ecs_scaling_target.service_namespace
target_tracking_scaling_policy_configuration {
target_value = 75.0
predefined_metric_specification {
predefined_metric_type = "ECSServiceAverageCPUUtilization"
}
scale_in_cooldown = 60
scale_out_cooldown = 60
}
}
당일 로그는 CloudWatch로 관리하고 있으며, 하루가 지난 로그는 S3로 전송 후, 제거하고 있습니다.
{
"server": "dailyge-api",
"path": "/api/monthly-tasks",
"method": "POST",
"traceId": "40cfde91-c912-4f3a-9b02-d45b3c066edb",
"ip": "127.0.0.1",
"layer": "ENTRANCE",
"visitor": "{ "userId":null, "role":"GUEST" }",
"time": "2024-08-06T07:29:48.745",
"duration": "0ms",
"context": {
"args": null,
"result": null
}
}
로그는 요청 경로, 메서드, IP 주소(Origin), 파라미터, 응답 시간 등을 남기고 있습니다.
데이터베이스는 매일 새벽 3시마다 스냅샷을 생성해 백업하고 있습니다.
데이터베이스 생성 후, AWS UI를 통해 설정을 관리하고 있으며, Import를 통해 싱크를 맞추고 있습니다.
modules 내부에 개발 환경을 기준으로 파일을 구분하고 있습니다. 명시적으로 dev, prod 패키지를 나누었지만, 프로젝트 규모가 작기 때문에 dev 하나만 사용하고 있습니다.
$ tree -L 5
.
├── dev
│ ├── graph.png
│ ├── main.tf
│ ├── modules
│ │ ├── acm
│ │ ├── cloudfront
│ │ │ ├── main.tf
│ │ │ ├── outputs.tf
│ │ │ └── variables.tf
|
│ ......
|
│ ├── provider.tf
│ └── variables.tf
......
Atlantis는 별도의 서버가 필요하기 때문에, 프로젝트 규모를 고려해 사용하지 않았습니다.